
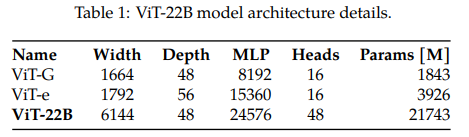
LLM(Large Language Model)의 크기가 10B~540B까지 넘어가는 동안, vison model에 대해서는 이 수준으로 scale을 키운 연구가 많지 않은 상황에서(당시 SOTA가 4B~15B 수준) Google Research에서 22B parameters를 가지는 ViT 모델을 효과적으로 학습하는 방법을 제안하는 논문을 냈습니다. (23년 02월)
주요한 내용을 꼽자면 아래와 같습니다:
1) 어떻게 ViT block을 변형해 22B까지 키울 수 있었는지
2) 22B의 parameters를 학습하기 위한 병렬 처리 기법 (using JAX)
–> 아직까지 JAX를 활용하는 곳이 많지 않기 때문에 1번 내용을 중점으로 리뷰하겠습니다.
(Model Architecture 부분만 보셔도 무방합니다)
참고:
Scaling vision transformers to 22 billion parameters
(오타나 잘못된 부분에 대해서 언제나 피드백 환영!)
목차
ViT-22B Model Architecture
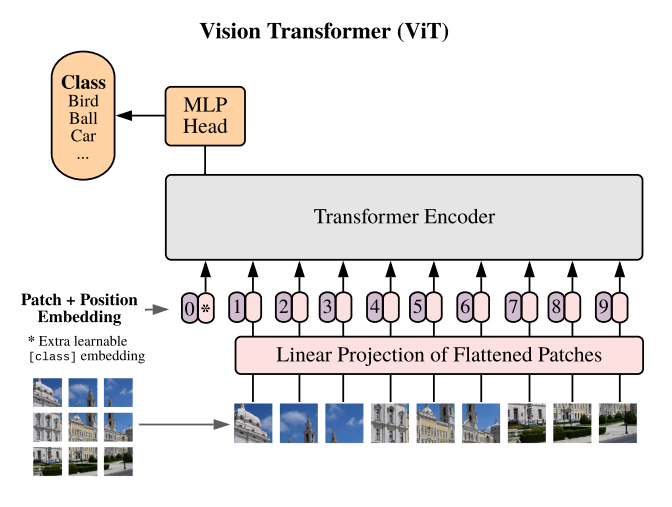
Transformer 베이스의 encoder 모델이고, 기존의 ViT와 동일한 구조(extracting image patches, linear projection, addition of learned 1D position embedding)를 가집니다.
대신 multi-head attention pooling을 사용함으로써 이미지 내의 여러 token 별로 생성 된 representation을 head에서 하나로 합쳐주었습니다.
또한 22B의 파라메터를 안정적으로 학습하기 위해서 transformer block을 개선했습니다.
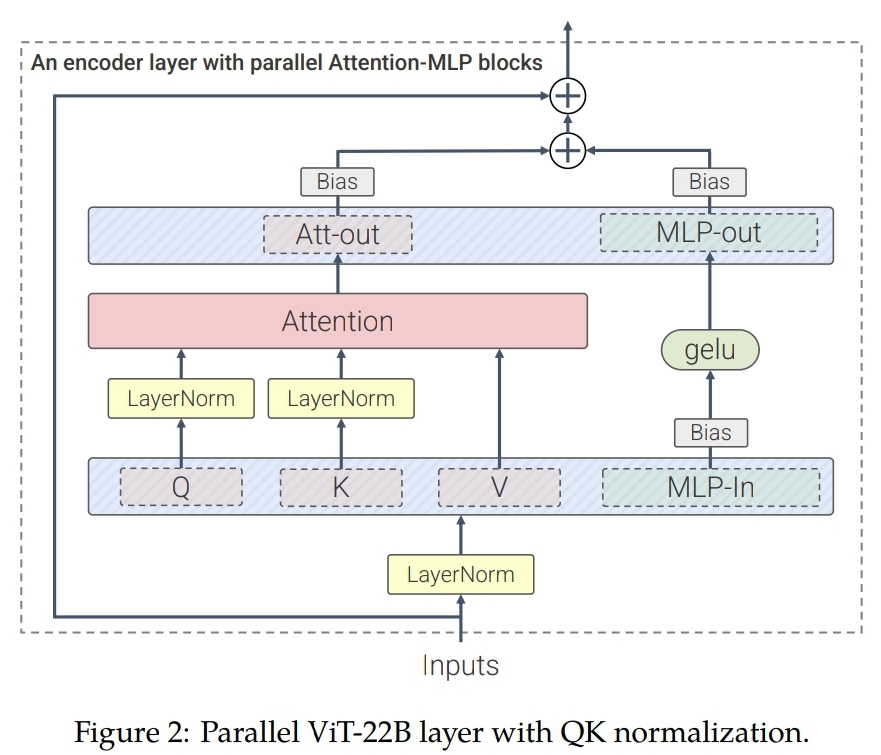
Parallel layers
기존 ViT block가 Attention layer -> MLP layer 를 순차적으로 가지는 것에 반해
ViT-22B는 Attention layer와 MLP layer를 병렬적으로 배치했습니다. (as GPT-J-6B)
$$ \begin{align}
y’ = \mathrm{LayerNorm}(x), \\
y = x + \mathrm{MLP}(y’) + \mathrm{Attention}(y’)
\end{align}$$
덕분에 성능 저하 없이 학습속도를 약 15%나 빠르게 개선할 수 있었습니다.
신기한 점은 65B의 큰 모델에서는 성능 저하가 없는 반면, 8B의 작은 모델에서는 성능 저하가 발생했다고 하네요.
Query/Key (QK) Nomalization
저자들이 ViT model을 8B로 키워서 학습해보니 1,000 step이 넘어가는 시점에서 loss가 터지는 이슈가 발생했다고 합니다. 그 원인으로는 학습이 진행될 수록 attention logits이 거의 one-hot에 가까워지다보니 entropy가 0에 가까워져서 loss가 터지는 것을 꼽았습니다.
✔ 해결책: attention layer에서 dot product 연산 전에 query & key 부분에 normalize를 해주기!
$$
\mathrm{softmax}[{1\over{\sqrt{d}}} \mathrm{LN}(XW^Q) (\mathrm{LN}(XW^K))^T]
$$
이러한 기법의 효과는 아래 그래프로도 확인해볼 수 있습니다.
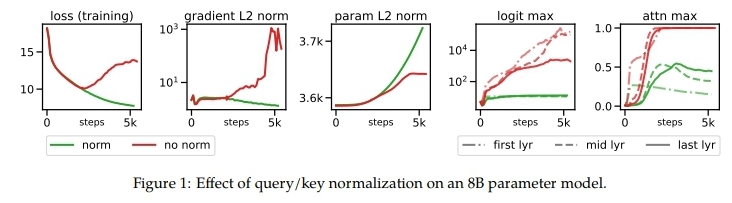
- normalize를 해주니 training loss가 안정적으로 줄어듦
- logit max도 레이어의 위치에 상관없이 학습 내내 일정하게 유지 됨
- attention max 값도 0.5 이하로 유지 (normalize안하면 max 값이 1에 수렴하는 것을 볼 수 있음)
Omitted biases on QKV projections & LayerNorms
PaLM 논문에서 제안된 것처럼 모든 QKV projection과 LayerNorm layers에서 bias 항을 제거했습니다. (성능 저하 없이 학습 속도가 빨라짐)
대신 ViT-22B에서는 ViT Block의 input/output MLP layers(그림에서 초록색 부분)에는 bias항을 추가해줬는데, bias항으로 인한 속도 저하 없이 오히려 성능이 개선이 됐기 때문입니다.
(Optional) Training Details
1. visual token
- patch size: 14 x 14 (image resolution: 224 x 224) –> 256 visual tokens
- Pre-processing: random horizontal flip –> inception crop
- High-resolution image에 fine-tuning:
pre-train 된 positional embedding에 2D interpolation (원본 이미지에서의 location에 따라서)
2. Hyper-parameters
- train 177k steps (w/ batch size: 65k) ~ 약 3epochs 학습
- lr_schedule: reciprocal square-root lr scheduler (w/ peak of e-3)
- Linear warm-up (1st 10k steps) –> cooldown (lask 30k steps)
- (for few-shot adaptation) using higher weight decay for upstream training:
– on the head: 3.0
– on the body: 0.03
Dataset (Pre-training)
JFT
- Google 논문 답게 JFT dataset을 사용
- 4B images w/ class-hierarchical한 30K개의 labels
–> Original ViT에 따라서 이 class-hierarchical labels를 flatten해서 multi-label classification
(Using Sigmoid cross-entropy loss)
Transfer learning to other tasks
Scale을 22B까지 키운 Foundation Vision Encoder의 성능을 알아보기 위해 여러가지 vision task들에 대해서 transfer learning 실험을 했습니다.
Image Classification
Image classification을 위해서는 3 가지의 방법으로 실험을 진행했습니다:
Linear Probing / Zero-shot / OOD(Out Of Distribution
Linear Probing
[ ImageNet-1K ]

ImageNet-1K에 대해서 linear probing(224 x 224)을 한 결과,
작은 모델을 high-resolution에 대해서 full-training한 것보다 성능이 좋았습니다.
즉, 잘 학습한 하나의 big vision encoder 하나만 있으면 열개의 작은 vision 모델들을 다시 고해상도로 재학습하는 것보다 좋다는 결론입니다.
[ iNaturalist 2017 ]
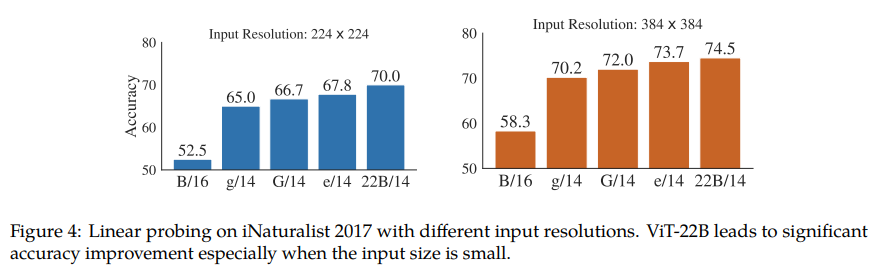
아래의 두 가지 특성:
. long-tail distribution
. dense한 label(5,089개 labels)
을 가지는 iNaturalist 2017 dataset에 대해서도 역시 기존의 다른 ViT 모델들을 뛰어넘는 성능을 보여줍니다.
저자들은 많은 parameter 개수를 가지는 모델이 image로부터 detailed informations를 잘 뽑아내는 것 같다고 합니다.
특히 image resolution이 작을 수록 다른 모델과의 성능차이가 확연합니다.
Zero-shot via locked-image tuning (LiT)
[ NOTE 💡] Locked-image Tuing (LiT) protocol 이란?
vision tower를 frozen하고, 여기에 text tower를 contrastively matching하는 것!
–> 이렇게 하면 zero-shot으로 classification & retrieval task를 수행 가능해짐
– Set ups:
. Vision Tower: frozen ViT-22B
. Text Tower: text transformer (w/ same size of ViT-g ) –> WebLI-en으로 contrastive learning
(1M steps w/ 32K batch_size 😮, 계산하면 320억개의 image-text pairs…!)
. Tokenizer: SentencePiece (trained on English C4 dataset) –> input text를 16개 token으로 자름
– results:
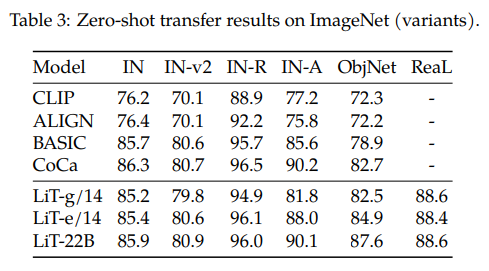
ImageNet 데이터셋에 대해서 꽤 준수한 few-shot 성능을 보여줍니다.
좀 더 어려운 데이터셋인 ObjectNet에 대해서도 역시 큰 ViT model일 수록 성능이 좋게 나오는 양상.
이렇게 학습한 모델은 위와 같이 인공지능(Parti, Imagen)으로 생성한 이미지들에 대해서도 zero-shot이 가능합니다. 인공지능으로 생성한 이미지들은 우리가 일반적으로 web에서 접할 수 있는 일반 이미지들과는 다른 분포를 가지기 때문에 OOD zero-shot 성능을 확인해볼 수 있습니다.
Out-of-distribution (OOD)
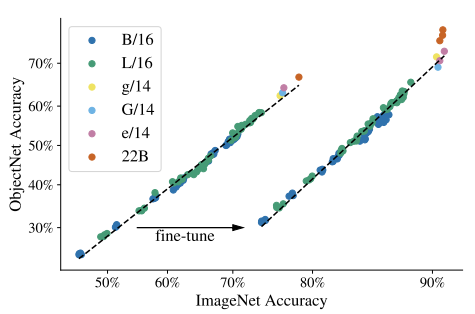
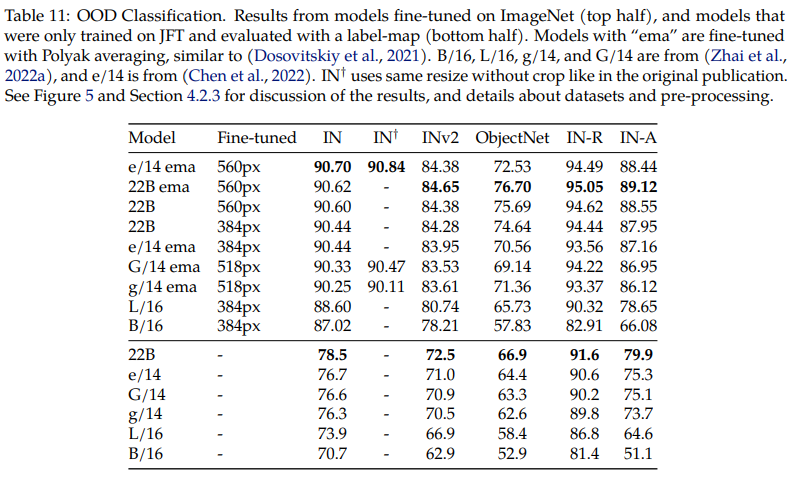
OOD case에 대해서 좀 더 살펴보기 위해서 1) JFT로만 학습한 경우와 2) ImageNet으로 fine-tuning한 경우를 살펴보겠습니다.
왼쪽 그래프에서 볼 수 있듯,
ViT-22B가 ImageNet과 OOD dataset(ObjectNet) 모두에 대해서 상회하는 성능을 보여줌을 확인할 수 있습니다. ImageNet으로 fine-tuning한 경우에 다른 ViT 계열의 모델들 역시 ImageNet에 대해서는 어느정도 saturation되는 성능을 보여주지만, ViT-22B가 학습에서 보지 못했던 OOD에 대해도 훨씬 robust함을 보여줍니다.
Dense Prediction
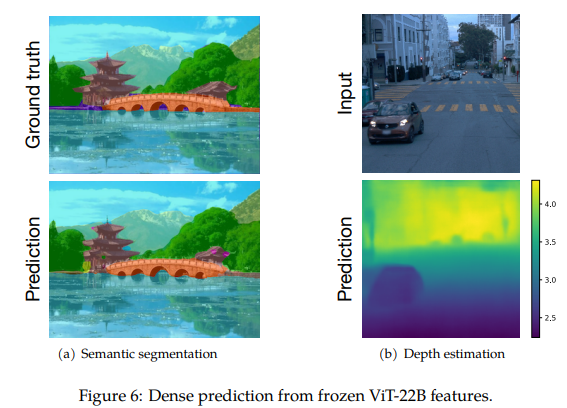
segmentation, depth estimation같은 dense prediction task의 경우에는 label이 pixel level로 주어지기 때문에 학습 비용이 많이 들지만, pre-trained ViT-22B를 활용하면 적은 개수의 data만으로도 좋은 성능을 얻을 수 있습니다.
Semantic Segmentation
[ ADE20K / Pascal Context / Pascal VOC ]
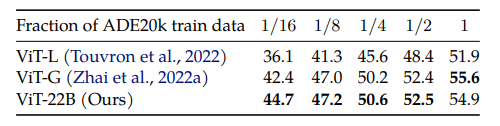
- E2E fine-tuning w/ linear decoder
- resolution: 504 x 504 px
- 1200장의 적은 ADE20K training set에 대해서 fine-tuning하는 경우, 다른 ViT 모델들보다 훨씬 좋은 성능을 보임 (training set이 커지면 다른 모델들도 결국 ViT-22B 성능을 따라잡음.)
- 즉, 적은 개수의 data로도 쉽게 fine-tuning이 된다는 것이 장점
Monocular depth estimation
[ Waymo Open real-world driving dataset ]
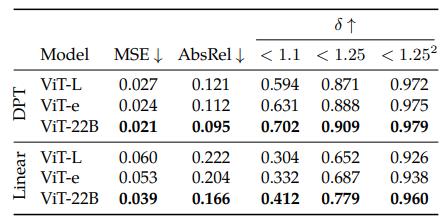
- Frozen ViT-22B + DPT(Dense Prediction Transfomer)를 붙여서 학습
(depth estimation의 경우 linear decoder를 붙이는 것보다 DPT 붙이는 것이 성능이 좋았다) - 가장 마지막 layer의 single feature map만 활용(∵ ViT의 high-dimensional feature를 잘 활용하려고)
Video Classification
Image로 학습한 모델이 Video input에서도 잘 적용되는지 확인하기 위해서 Video Classification을 진행했습니다.
[ Kinetics 400 / Moments in Time ]
– Setups:
. 각 데이터셋 별로 stride 2로 frame을 샘플링
–> Kinetics 400: 128 frames / Moments in Time: 32 frames
. ViViT의 Factorised Encoder 구조를 따름 (아래)
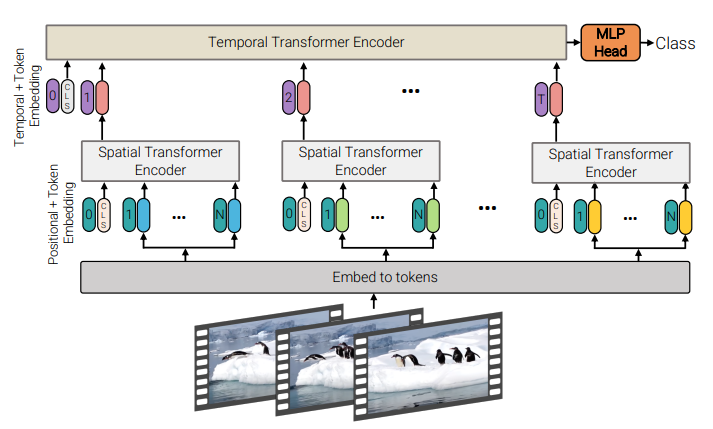
. (As ViViT) 2개의 transformer encoder를 가지는데:
– Spatial Transformer Encoder:
. pre-trained ViT-22B로 init & freeze
. 각 frame 별로 encoding을 진행해서 single embedding을 뽑음 (마지막에 pooling해서 한개로 만듦. 위 그림에서 코랄색 token)
– Temporal Transformer Encoder:
. shallow transformer encoder (ViT에서는 63.7M 짜리를 사용했는데, 22B에 비하면 shallow한 편)
. video class-token classifier가 붙어있음.
. 위에서 구한 frame-level representations를 concat해서 넣어줌
이 두 가지 encoder를 late fusion 방식으로 사용합니다.
– results:
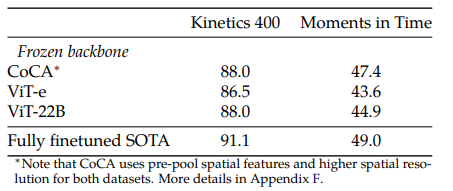
단순히 224px의 Image만 가지고 학습한 ViT-22B가 CoCa:
1) 576px의 고해상도의 frame에 대해서 학습, 2) contrastive & generative caption pretrained, 3) 한 frame에 대해서 더 많은 개수의 token을 사용하는 모델과 비교했을 때 Kinetics 400에 대해서는 동등한 수준의 성능을 보인다는 점이 놀랍습니다.
효율적인 학습을 위한 병렬 학습 (using JAX)
Asynchronous parallel linear operations
FLOPs의 많은 부분을 차지하는 matrix multiplication을 효율화하기 위해서 k 개의 GPU device에 비동기적으로 분산시켜 연산을 수행했습니다.
이를 위해서 model weights와 input(혹은 중간 레이어에서의 activations)를 k 개의 multi-device에 나누어 뿌려줍니다. 즉, 각 device에서는 1/k만큼의 model weights와 input(혹은 중간 레이어에서의 activations)만 가지고 연산을 수행하면 됩니다. 분산 전후로 결과가 동일하게 나오게 만들기 위해서 멀티 디바이스들은 1/k 짜리 input(activation)을 서로 바꿔가며 연산을 마저 합니다. 통신으로 인한 오버헤드를 방지하기 위해서 이 1/k짜리 input의 통신은 비동기적으로 이루어집니다.
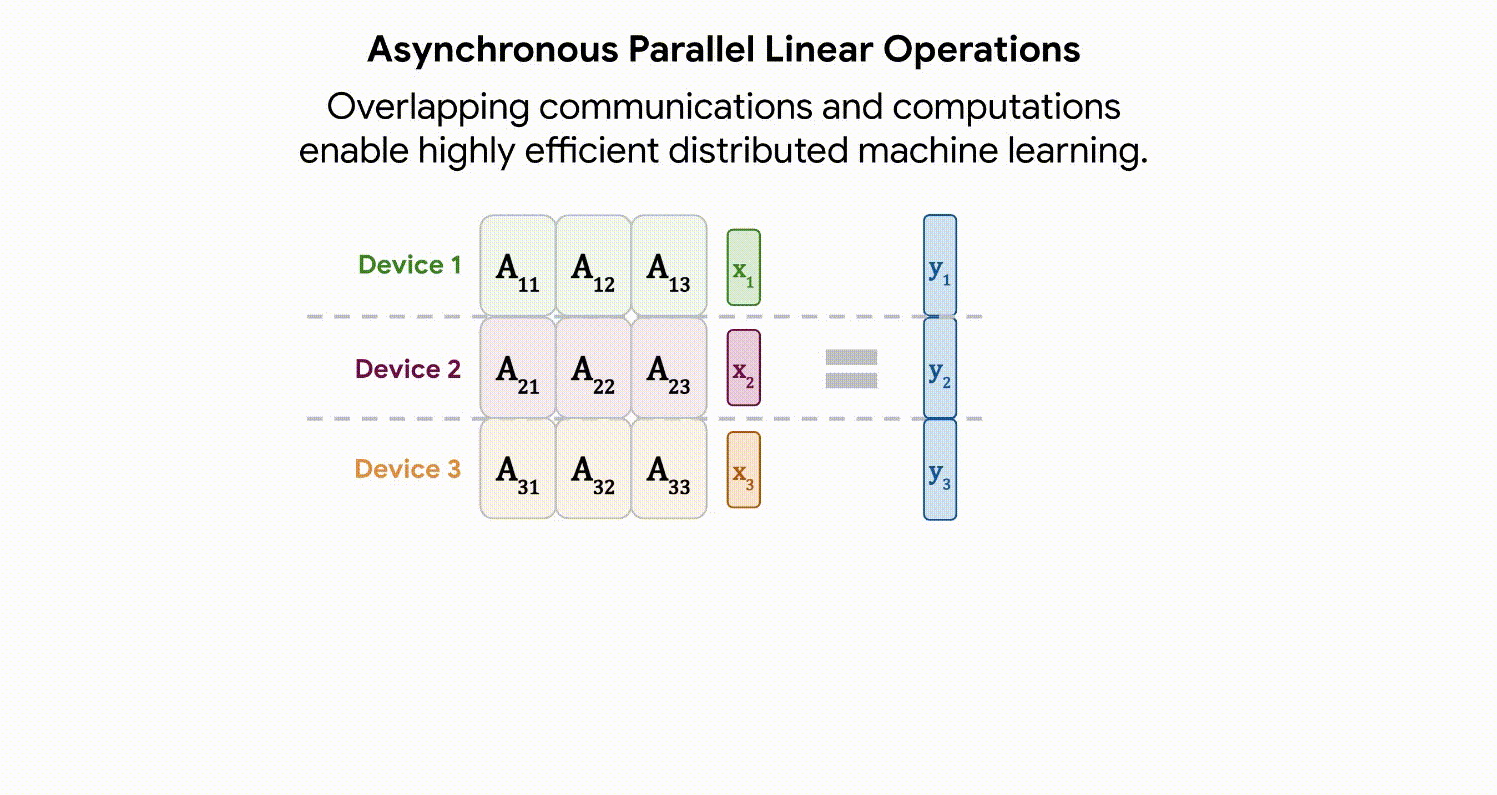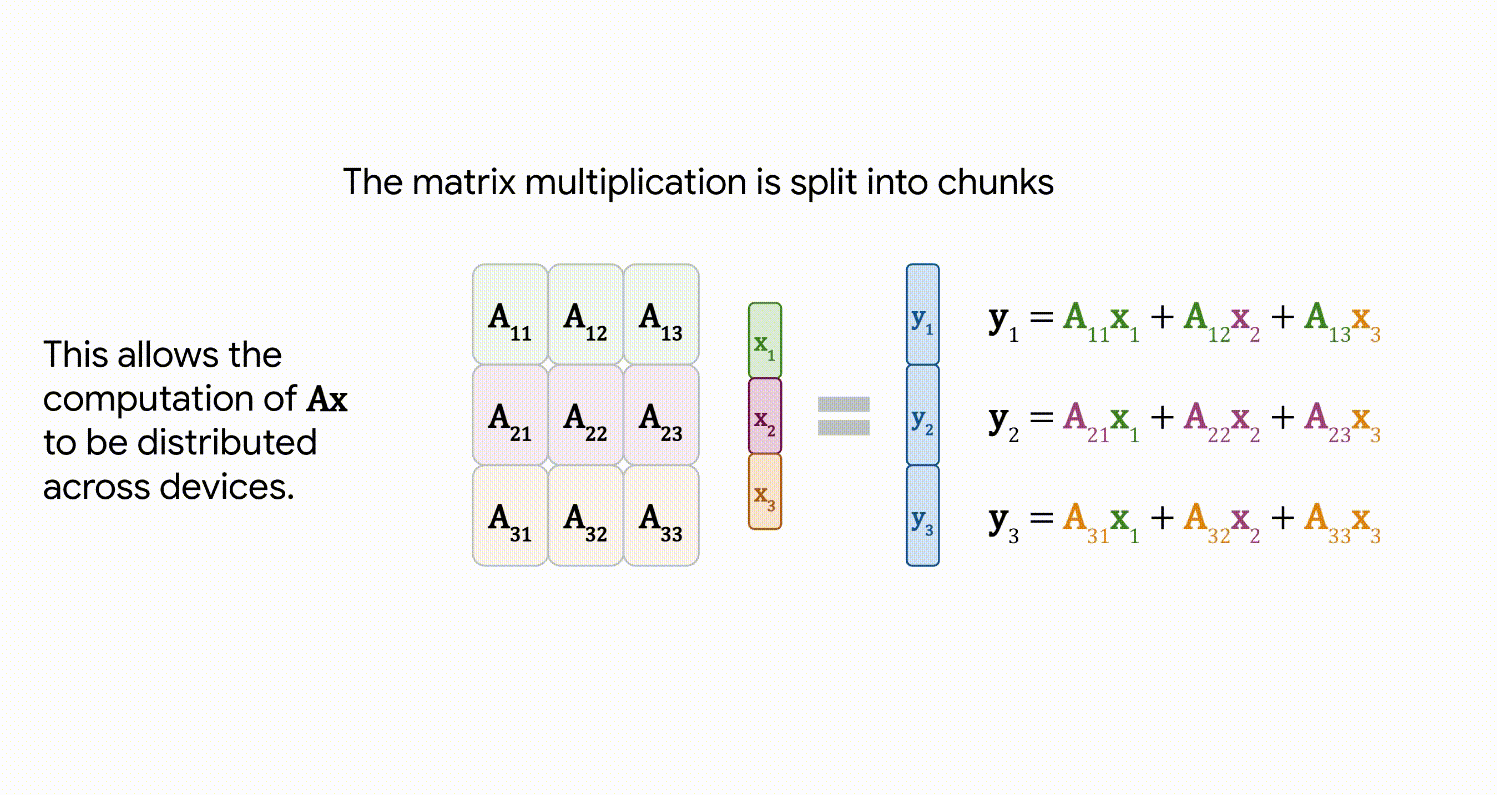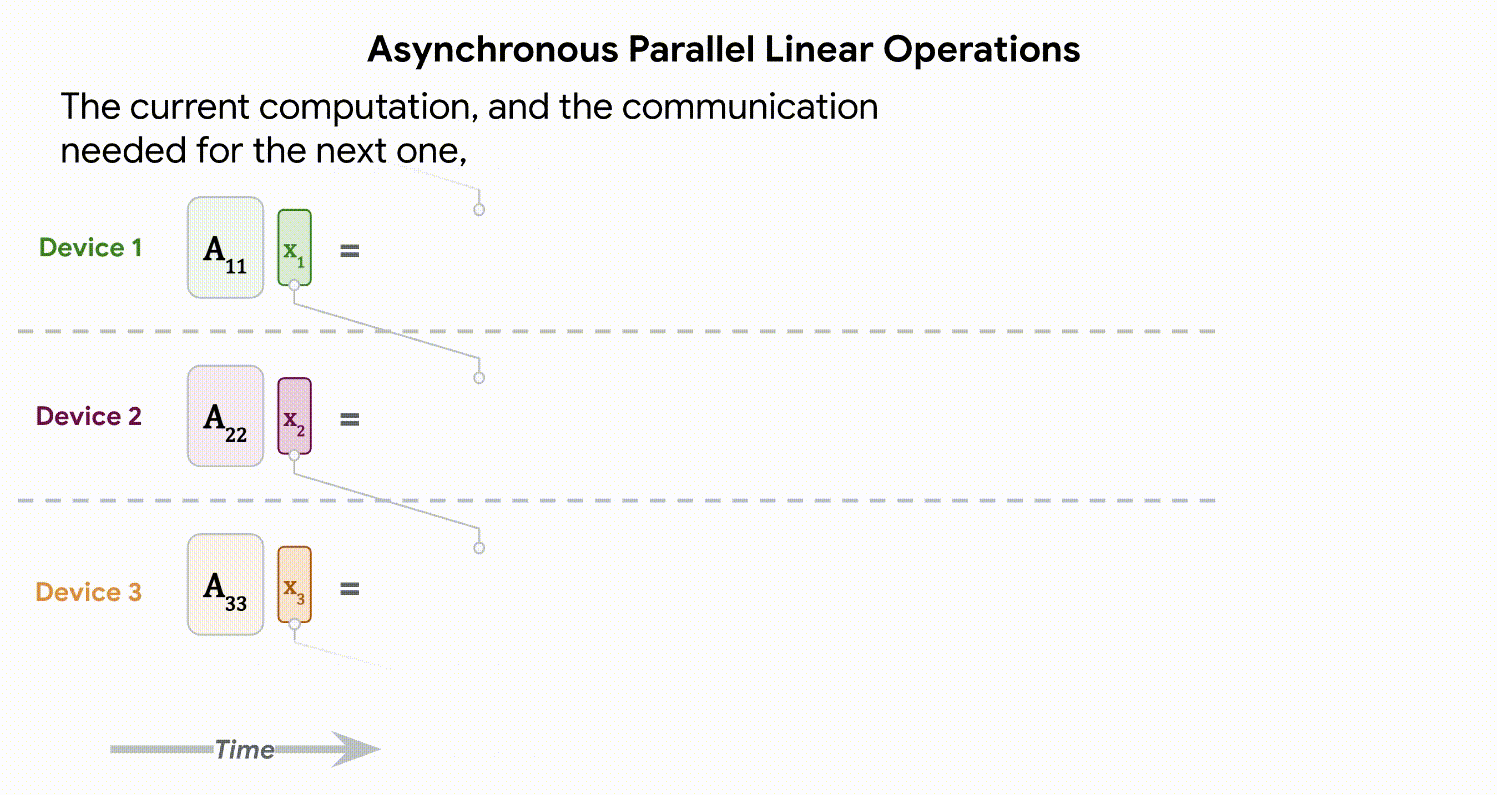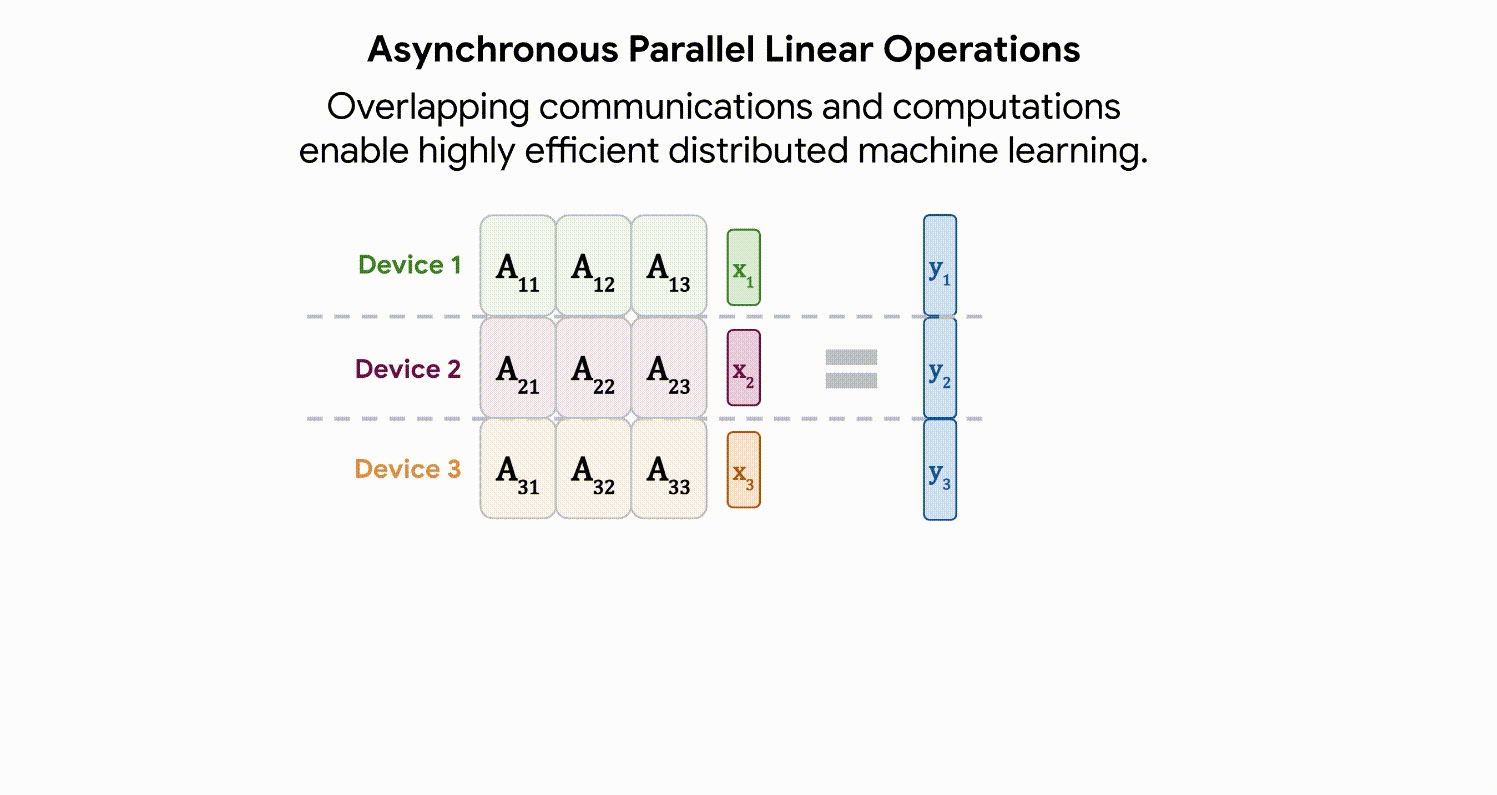
위 그림처럼 각 device는 1/k 만큼의 activation과 1/k 만큼의 weight를 가지고 연산을 하기 때문에 효율적인 연산이 가능해집니다.
inputs(=activations)를 각 device에 어떤 방식으로 나누어서 (row 방향으로 자를지, column 방향으로 자를지) 뿌려줄 것인지는 Weight matrix의 형태에 따라 결정됩니다.

ViT-22B에서는 y = Ax 라는 행렬 곱셈을 계산하는 경우 (A는 m X n 행렬),
n = 4m 이라면 transformer의 MLP output을 계산할 때 column sharding(아래쪽)을 해주고,
그 외에는 row sharding을 적용했습니다.
하드웨어적인 부분인 것 같아서 자세한 내용은 구글 블로그와 논문 내용을 참고하세요.
Parameter sharding
모델 파라메터 뿐만 아니라 학습 데이터 양도 많기 때문에 학습에 data-parallelism이 적용됐습니다.
때문에 모든 device가 동일 시점의 weight 전체나 일부 chunk를 들고 있어야 합니다.
또한 forward 시에는 이 parameter들을 합쳐주고, backward 시에는 다시 뿌려줘야 한다고 하네요.
복잡하지만.. 이 모든 과정이 모두 비동기적으로 이뤄지기 때문에, 각 레이어는 연산을 수행하면서 다음 step에 대한 준비(weight 가져오기 위한 통신)를 수행함으로써 통신 관련 오버헤드를 줄였다고 합니다.